- Published on
How to Deploy Ollama Server on Amazon EC2 with GPU in 10 Minutes
- Authors

- Name
- Ligang Yan
- @alinlinlink
Welcome to our comprehensive guide on how to deploy Ollama Server on an Amazon EC2 instance with a GPU in 10 minutes.
This guide is ideal for individuals or small teams building their own open source local large language model (LLM) AI capabilities in the cloud, ensuring data privacy, customizability, regulatory compliance, and cost-effective AI solutions.
In this guide, we'll walk through the process step-by-step, providing detailed instructions and references to ensure a smooth setup.
LLM and Ollama
To deploy a large language model and provide services to the outside world, LLM and Ollama not only require high-end GPUs, but also extensive technical expertise, which makes many people only rely on API services provided by large companies, such as OpenAI's GPT- 3 or Google's BERT.
However, the open source project llama.cpp has achieved the 'democratization' of AI by optimizing the CPU and simplifying the deployment method, which means that individual developers or small teams can also deploy their own AI services in the cloud.
Ollama is a project based on llama.cpp. It provides a more friendly API interface that can directly call AI services through HTTP requests. It supports deployment on macOS, Linux, Windows, and cloud deployment, and supports GPU acceleration.
Deploy Ollama on EC2
Step 1: Create EC2 instance
The following configuration list is the configuration of an EC2 instance with GPU acceleration. Although Ollama also supports running with only CPU, the inference speed will be slower, so we choose an instance with GPU.
Note: After you apply to create a G-class instance, you may receive a creation failure notification from AWS, requiring you to apply for a quota first. The notification will include a link. The application process takes about half a day. After approval is passed, create the instance again.Configure an Amazon Linux 2 EC2 instance:
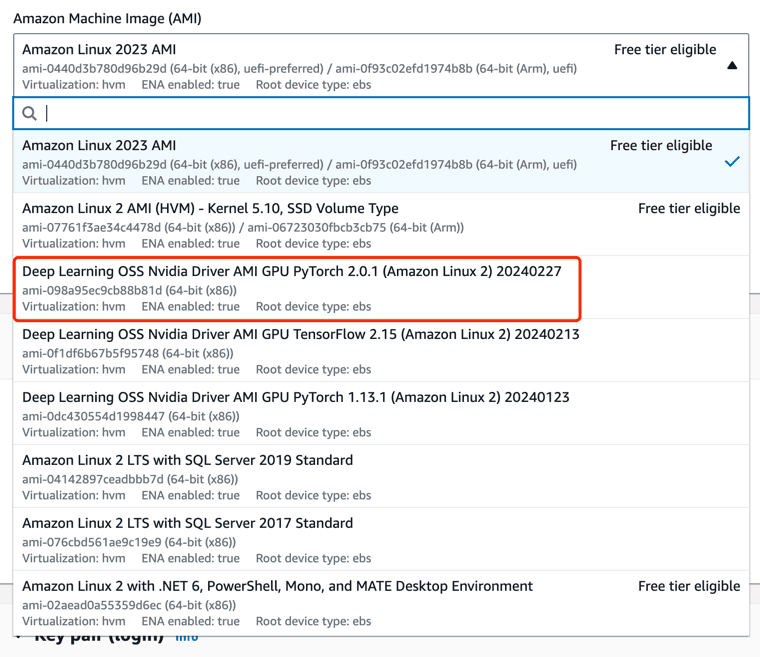
- Amazon Machine Image (AMI): Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.0.1 (Amazon Linux 2) 20240227
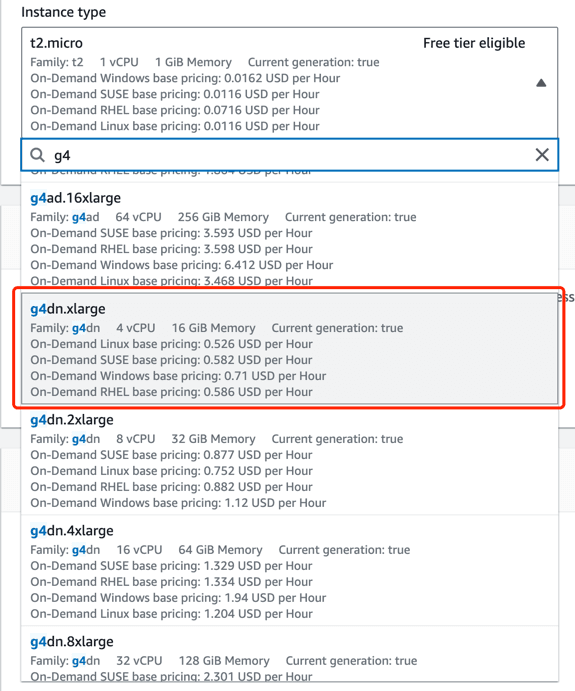
- Instance Type: g4dn.xlarge ($380/month https://calculator.aws)
- vCPU: 4
- RAM: 16GB
- EBS: 50GB (gp3)
Step 2: Install and deploy Ollama
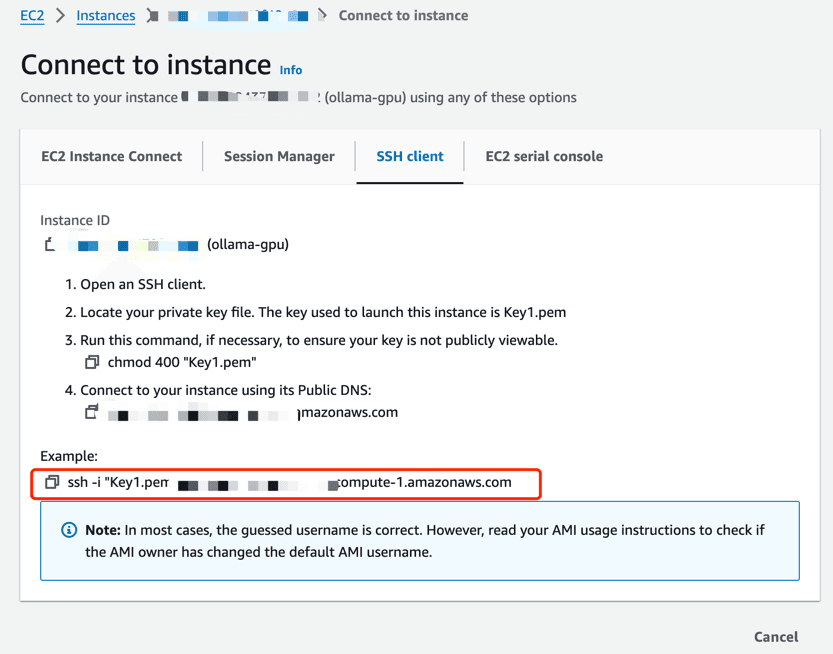
We use ssh to log in to the EC2 instance, and then execute the following command to install Ollama.
ssh -i "Key1.pem" ec2-user@ec2-3-228-24-35.compute-1.amazonaws.com
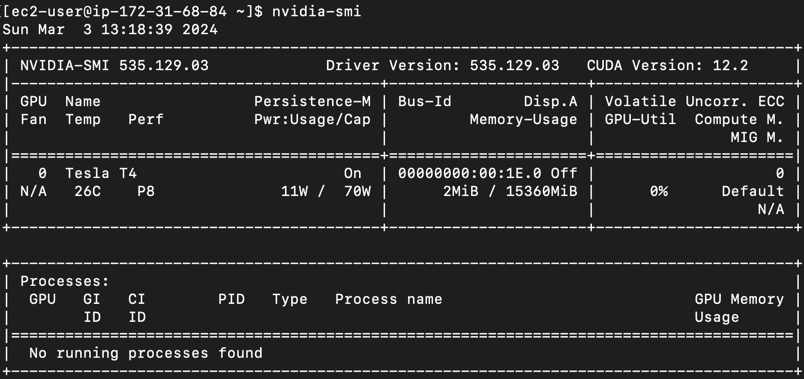
Check whether the Nvidia driver is installed successfully
nvidia-smi
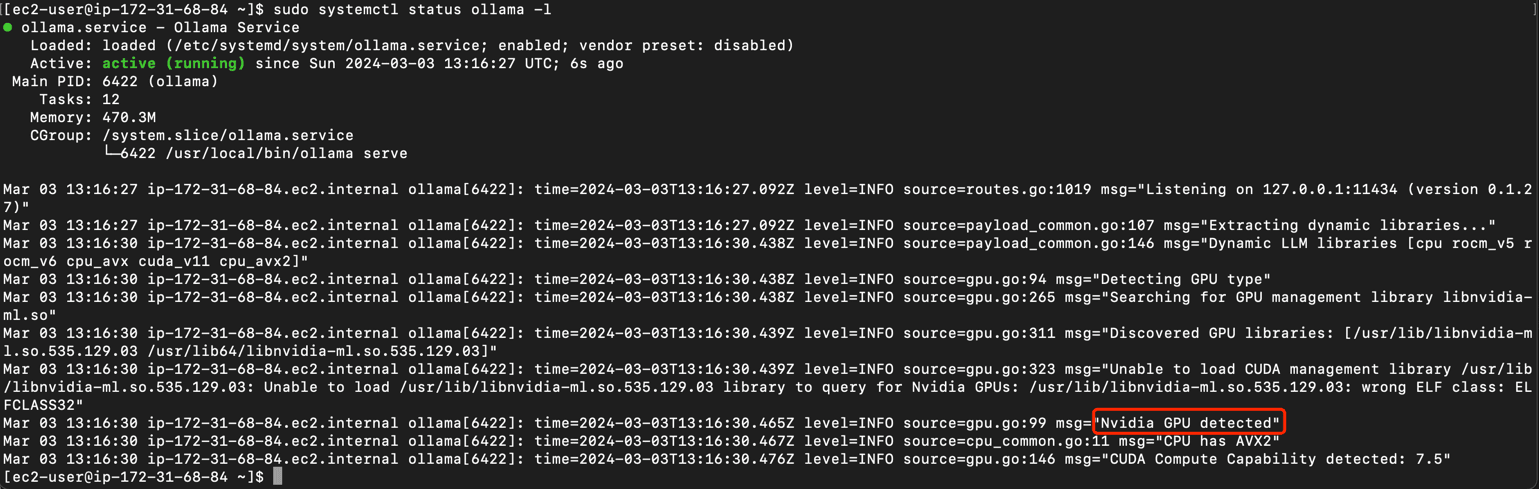
Install Ollama and check the service status. As shown in the picture, if the log reminds Nvidia GPU Detected, it means that Ollama has successfully detected the GPU.
curl -fsSL https://ollama.com/install.sh | sh
sudo systemctl status ollama
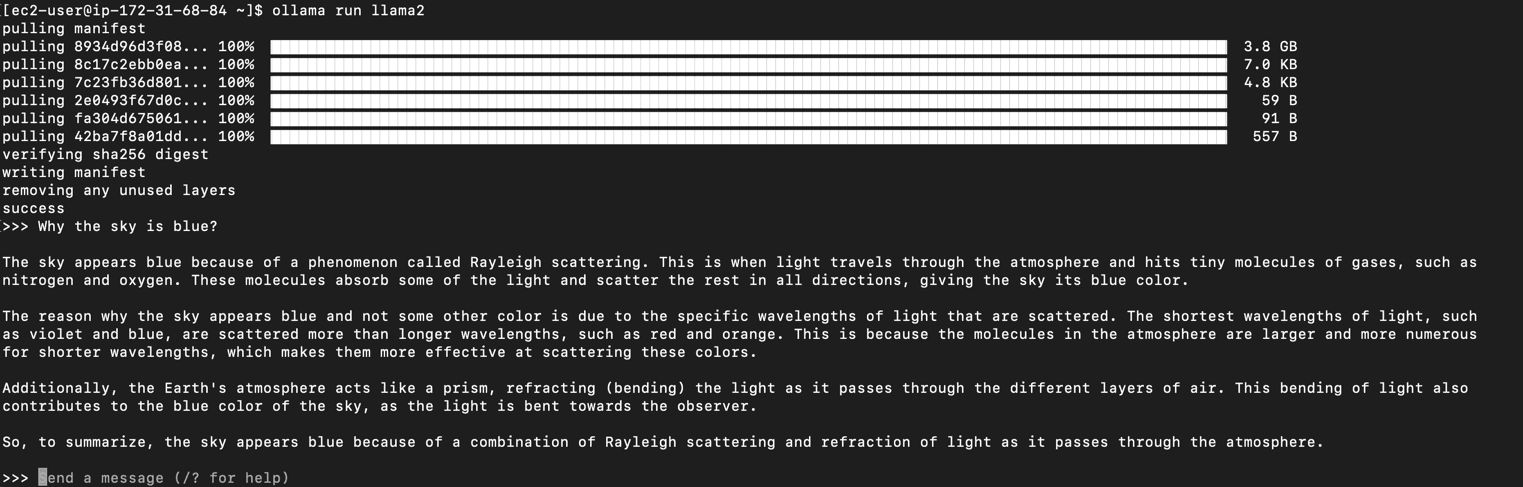
Step 3: Run the llama2 model
After Ollama is installed, we can try to run an llama2 model to test whether the Ollama service is normal and whether GPU acceleration has been started.
ollama run llama2
Step 4: Install and configure Nginx
Next, we plan to install Nginx as a reverse proxy, forward requests from port 80 to port 11434, and provide services to the outside world.
sudo amazon-linux-extras install nginx1
sudo vim /etc/nginx/conf.d/myapp.conf
server {
listen 80;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Restart Nginx to make the configuration take effect
sudo systemctl restart nginx
Step 5: Install and deploy open-webui
open-webui It is an open source front-end project that provides a friendly interface to call Ollama services.
We are now using docker locally to quickly deploy an open-webui service and specify the Ollama URL to test the effect. Make sure you have docker installed locally, then execute the following command
Replace x.x.x.x in https://x.x.x.x/api with the public IP address of your EC2 instance
docker run -d -p 3000:8080 -e OLLAMA_API_BASE_URL=https://x.x.x.x/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Summarize
To quickly deploy an Ollama service with GPU on AWS EC2, a very important point is that AWS provides pre-configured AMI (Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.0.1 (Amazon Linux 2) 20240227) This AMI is pre-installed with Nvidia drivers, which saves us a lot of installation and configuration time. It switches almost perfectly with Ollama and works right out of the box.
Another important point is the configuration of Nginx. Through Nginx's reverse proxy, we can provide Ollama services to the outside world, and we can use Nginx configuration to do load balancing, current limiting, etc. We can also add identity authentication, logging and other functions in the future. .
Ads
mistreeai.com is an AI character chat website with no censorship or filtering. Here you can have creative and interesting conversations with hundreds of real or virtual characters.