- Published on
How to Design a PDF Text-to-Speech Service Like Speechify
- Authors

- Name
- Ligang Yan
- @alinlinlink
Text-to-speech (TTS) services have become a popular tool for making content more accessible, providing convenience for users who prefer listening to their text rather than reading it. One of the most well-known TTS platforms is Speechify, which converts digital text, including PDFs, into high-quality audio. When I embarked on building a PDF text-to-speech service similar to Speechify, I faced several challenges and opportunities. In this article, I’ll take you through the steps of how I system-designed this service, from understanding user needs to choosing the right technology stack and scaling the solution.
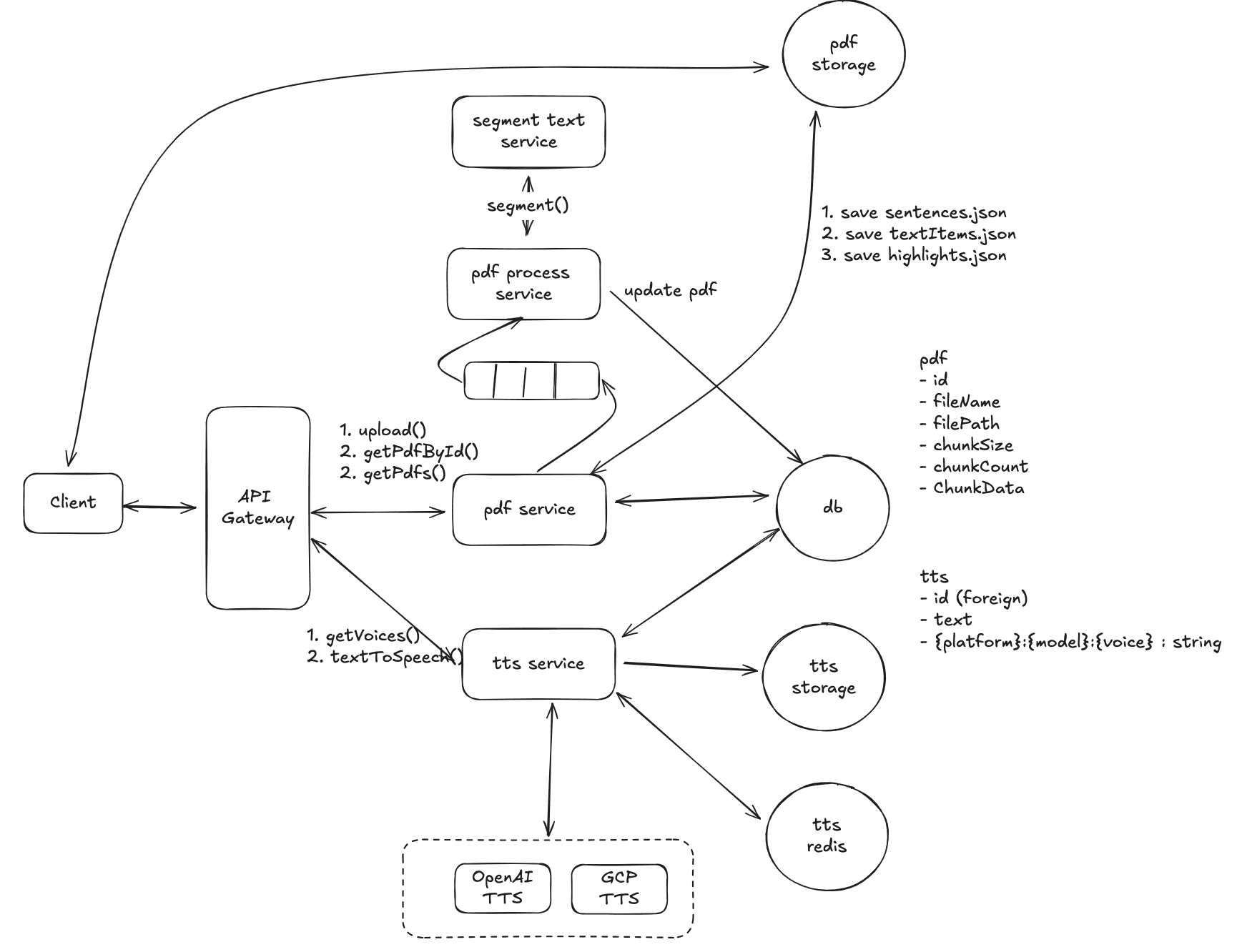
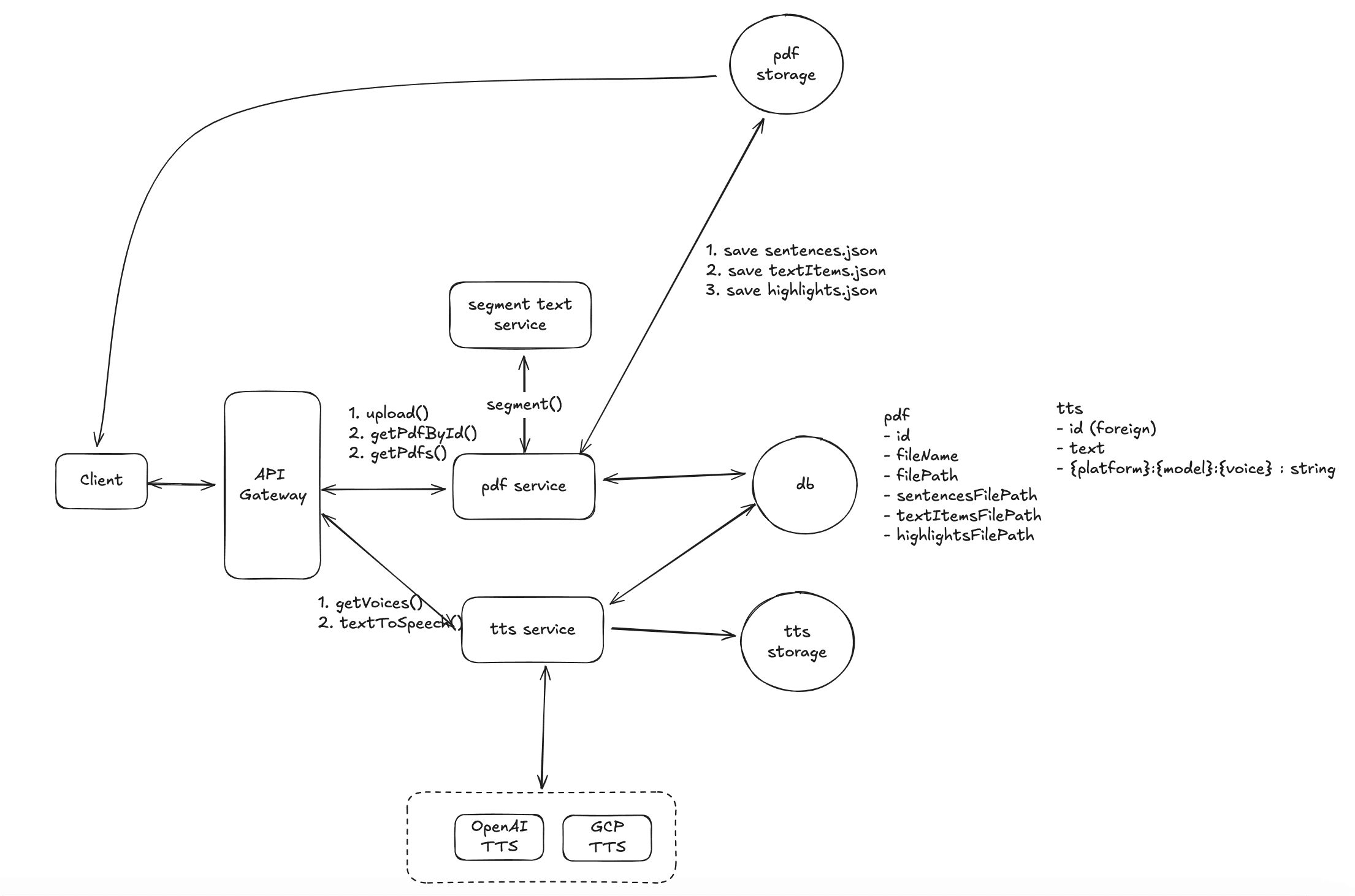
The final high-level system architecture diagram is shown below:
AD: DocWiser.com an alternative to Speechify.
Understanding the Problem:
Functional Requirements:
Before diving into the architecture and design, I needed to clearly define what the service should offer. Here are the core features I identified for my PDF text-to-speech service:
- Users should be able to upload PDF files
- Users should be able to access a list of uploaded PDFs and preview individual pdf files.
- Users should be able to click a button and trigger the system to read the text from start
- Users should be able to click any text within the PDF, and trigger the system to read the selected text aloud, followed by automatic reading of the next sections.
- Users should have the option to adjust the voice and playback speed.
Non-Functional Requirements
- The system must be able to process large PDF files quickly, even those hundreds of megabytes in size, completing the task within seconds.
- The document reading should start with extremely low latency, under 100ms, and there should be no noticeable delay during continuous reading.
- The system should be able to support 1 million daily active users.
- The system must be highly reliable, with 99.99% uptime, prioritizing availability over consistency.
Capacity estimation
Capacity estimation helps us evaluate the scale of the system in advance, allowing us to understand how much computational and storage resources will be needed under certain assumptions. It also helps the scalability of the design, consider costs, and evaluate performance and reliability.
Assumptions:
- 1 million daily active users.
- Each user uploads a 1MB document daily.
- Each user requests 5 times the PDF lists and PDF details daily.
- Each user listens to 1 hour of TTS daily.
Estimation:
- Document Listing Requests:
- Each user requests their document list 5 times a day.
- 1 million users/day * 5 requests/user = 5 million requests/day
- 5 million requests/day ÷ 100,000 requests/second = 50 requests/second
- Document Detail Requests:
- Each user requests document details 5 times a day.
- 1 million users/day * 5 requests/user = 5 million requests/day
- 5 million requests/day ÷ 100,000 requests/second = 50 requests/second
- Document Upload Requests:
- Each user uploads 1 document (1MB) daily.
- 1 million users/day ÷ 100,000 requests/second = 10 requests/second
- TTS Audio Generation
- 1 hour of audio ≈ 50,000 characters (assuming 1 sentence = 100 characters)
- 50,000 characters ÷ 100 = 500 sentences per document
- 500 TTS requests per user per day
- 500 requests/user * 1 million users/day = 500 million TTS requests/day
- 500 million requests/day ÷ 100,000 requests/second = 5,000 TTS requests/second
Storage Requirements:
- PDF Storage:
- 1 million users/day * 1MB document * 365 days/year
- Total: 365 million MB = 365 TB annually
- Audio Storage:
- Assuming each sentence of TTS audio is 0.1MB:
- 1 million users/day * 500 sentences * 0.1MB * 365 days/year
- Total: 18,250 TB annually (50 million MB/day * 365)
The Set up
Defining the Core Entities
We define the core entities involved in handling PDFs and generating TTS (Text-to-Speech) output, as well as managing the different voices available for TTS.
id: Unique identifier for the PDF.fileName: The name of the PDF file.filePath: The storage location of the PDF (e.g., cloud storage path or local server path).
TTS (Text-to-Speech)
id: Unique identifier for the TTS.text: The text to be converted into speech.{platform}:{model}:{voice}: Unique string identifier combining platform, model, and voice options for the TTS request (e.g., AWS:Polly:Neural, Google:Standard:EnglishA).
Voice
id: Unique identifier for the voice.platform: The TTS platform (e.g., AWS Polly, Google Cloud Text-to-Speech).model: The voice model (e.g., Neural, Standard).voice: The specific voice option (e.g., "Joanna").languageCode: The language code for the voice (e.g., "en-US").voiceName: The human-readable name of the voice (e.g., "Joanna").
API or System Interface
To interact with the system, we define the following REST API endpoints for handling PDF uploads, retrieving available voices for TTS, and submitting TTS requests.
PDF Management API
Upload a PDF
- Endpoint:
POST /docs - Request Body:
{ "fileName": "example.pdf", "filePath": "/uploads/example.pdf" }- Response: Success or error message with
idof the uploaded PDF.
- Endpoint:
List all PDFs
- Endpoint:
GET /docs - Response:
[ { "id": "1", "fileName": "example.pdf", "filePath": "/uploads/example.pdf" }, ]- Endpoint:
Retrieve a Specific PDF by ID
- Endpoint:
GET /docs/:id - Response:
{ "id": "1", "fileName": "example.pdf", "filePath": "/uploads/example.pdf" }- Endpoint:
TTS (Text-to-Speech) API
- List Available Voices
- Endpoint:
GET /tts/voices - Response:
[ { "id": "1", "platform": "AWS Polly", "model": "Neural", "voice": "Joanna", "languageCode": "en-US", "voiceName": "Joanna" }, ] - Endpoint:
- Submit a TTS Request
- Endpoint:
POST /tts - Request Body:
{ "text": "Hello, welcome to our platform!", "platform": "AWS Polly", "model": "Neural", "voice": "Joanna", "languageCode": "en-US" } - Endpoint:
- Response: Success message with
idof the generated TTS file or error message
High-Level Design
Let's begin with a simple scenario to design our system. Assume we have a PDF file with only one page, and each line is a complete sentence. For example:
Hello Everyone. I'm Allen. Nice to meet you.
1. Basic Workflow
- Step 1: Upload the PDF file to storage (e.g., cloud storage like AWS S3).
- Step 2: The storage returns the file path.
- Step 3: Call the
upload()backend API to save PDF information (like fileName and filePath) into the database. - Step 4: The client can call the
getPdfs()API to retrieve the list of PDF files. - Step 5: The client can call the
getPdfById()API to retrieve specific PDF details, including the file path. - Step 6: On the client side, use the react-pdf library to display the PDF document, passing the file path as an argument.
- Step 7: Use the pdfjs-dist library on the client side to parse the content of the PDF document, extract all the sentences.
- Step 8: For each sentence, call the
textToSpeech()API to get the TTS (Text-to-Speech) audio URL. - Step 9: Play the audio directly using the provided URL.
2. Text-to-Speech Caching Mechanism
To optimize the system, we can cache the TTS results. When we make a textToSpeech() request, we generate a unique ID using the MD5 hash of the sentence, which allows us to reuse the same audio file without re-generating it for identical inputs. Different platforms, models, or voices will generate different file paths, but they will be grouped under the same ID.
For example:
{
"id": "jAR8eju7eZS9LN5RP9TP77jG3lnnEsNQaZ_QAspBo",
"text": "Hello Everyone. I'm Allen. Nice to meet you",
"google-standard-EnglishA": { "filePath": "/tts/google/EnglishA.mp3" },
"openai-tts-1-alloy": { "filePath": "/tts/openai/Alloy.mp3" }
}
- The key
"jAR8eju7eZS9LN5RP9TP77jG3lnnEsNQaZ_QAspBo"is the MD5 hash of the text. - The platform, model, and voice combination (e.g.,
google-standard-EnglishA,openai-tts-1-alloy) map to different TTS audio file paths.
This way, if a user requests the same sentence with the same TTS parameters, the system can retrieve the cached result from storage instead of regenerating the TTS file. This reduces redundant TTS generation, saving time and computational resources.
3. Separation of PDF and TTS Services
We separate the PDF service and TTS service for scalability reasons:
- From the capacity estimation, we know that TTS requests have approximately 500 times more concurrency than PDF-related operations.
- The TTS service will need to scale horizontally much more than the PDF service.
- Each service will operate independently, with its own scaling requirements.
4. Database Choice
Given that:
- There are no complex relationships between tables (i.e., no need for foreign keys or joins).
- The TTS service will handle a large volume of write operations due to high concurrency.
A NoSQL database, such as MongoDB or DynamoDB, would be a more suitable choice for storing both PDF and TTS data. NoSQL databases are optimized for high write throughput and can easily scale horizontally, making them ideal for this use case.
This high-level design provides a simple and scalable architecture that separates the PDF service and the TTS service to handle different levels of concurrency. By caching TTS results using MD5 hash keys, we avoid redundant TTS generation, improving performance. The use of NoSQL databases ensures efficient handling of high write throughput. This architecture can easily be extended to handle additional use cases and higher user loads.
Potential Deep Dives
1. Handling Large PDF Files
In the first version of our system design, there's a significant issue when dealing with large PDF documents. If a client requests TTS for a large PDF all at once, the latency will be very high. To solve this, we can make improvements by breaking the text into smaller chunks. Here are two possible solutions:
Solution 1: Client-Side Text Extraction and Segmentation
Process:
- The client extracts the entire text from the PDF and uses a regular expression to split it into smaller sentences based on punctuation (e.g., periods, question marks, exclamation points).
- Each sentence is then sent as a separate request to the server’s TTS API for conversion to audio.
Advantages:
- Simple Handling: It keeps the logic relatively simple, and the server remains unchanged.
- Smaller Requests: The TTS requests will be smaller and faster, reducing server-side processing time for each request.
Disadvantages:
- Inaccuracy of Regex: Using regular expressions may not always yield accurate sentence segmentation. For example, abbreviations like "Mr.", numbered lists (e.g., "1."), or other special cases can cause incorrect splits.
- Reprocessing Each Time: Every time the document is opened, the client will need to reprocess and apply the split logic, potentially causing delays or a laggy user experience.
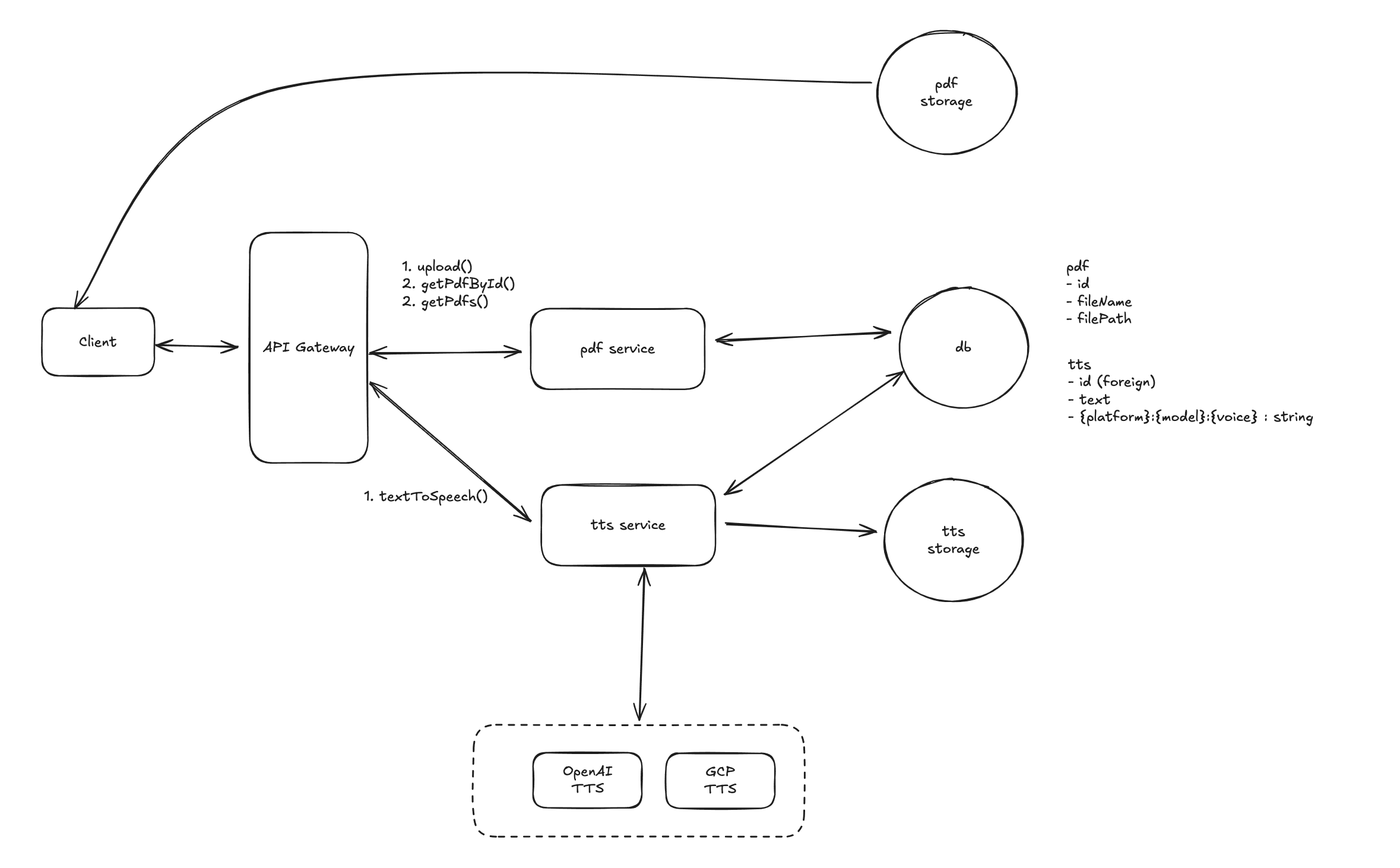
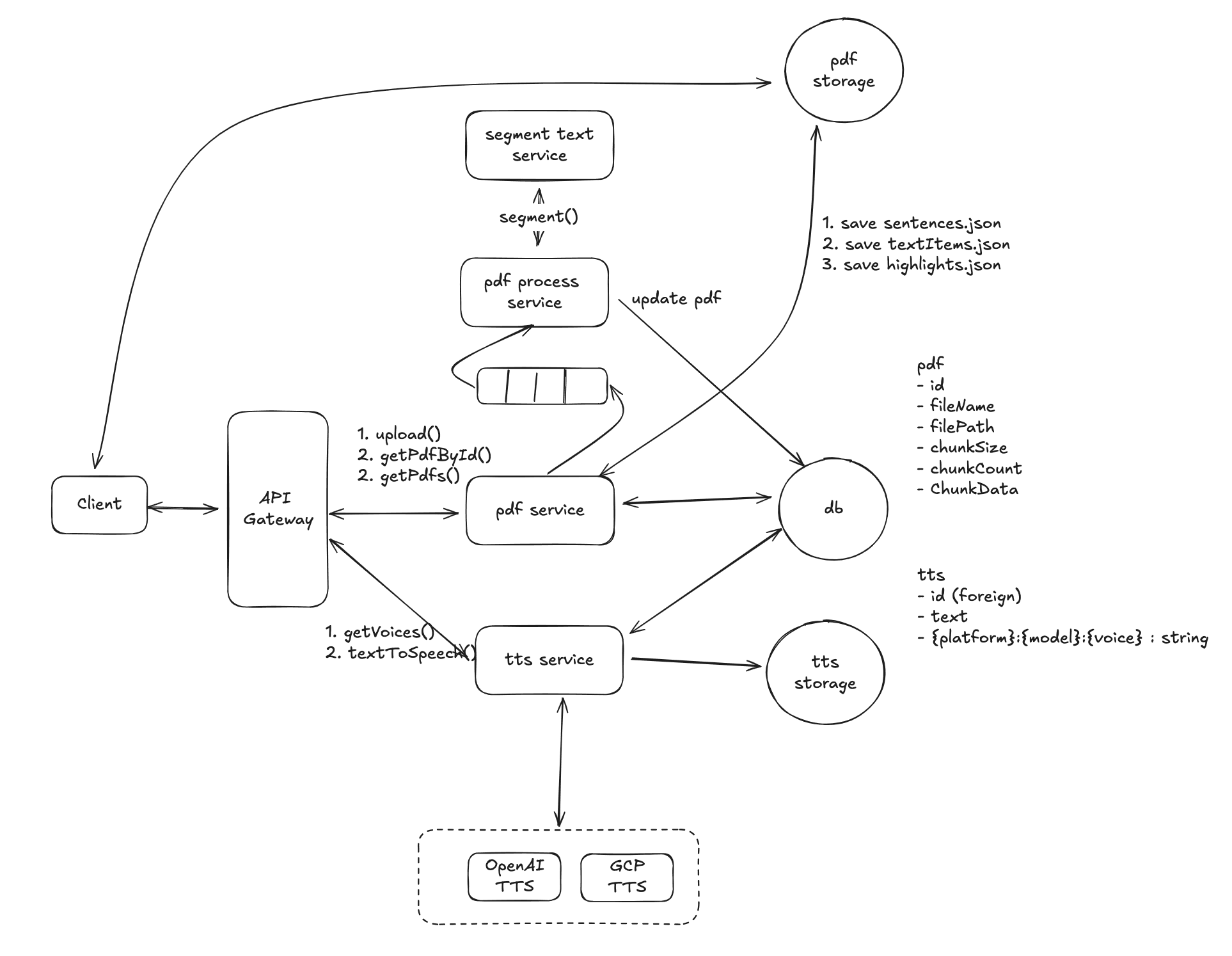
Solution 2: Server-Side Text Segmentation during PDF Upload
- Process:
- When a user uploads a PDF document, the server immediately processes the PDF to extract all text.
- The server uses a segment text-to-sentences service that splits the text into smaller, properly segmented sentences.
- The segmented sentences are saved as a
.jsonfile, which is stored in cloud storage. - When the client requests TTS for a PDF, it fetches the pre-processed
.jsonfile with all sentences already split, and each sentence can be processed individually.
What is a Text Segmentation Service?
- A text segmentation service is an advanced text processing tool that uses natural language processing (NLP) techniques to split any text into sentences more accurately than simple regular expressions. It can handle complex sentence structures, abbreviations, and punctuation rules, producing more reliable segmentation results.
- Example: Given the text "Dr. Smith is here. She arrived at 10:00 a.m. Can you see her?" a proper NLP segmentation tool would correctly interpret "Dr." and "a.m." without incorrectly splitting the sentences.
some potential NLP libraries for text segmentation:
- spaCy: A popular NLP library that provides sentence segmentation capabilities.
- NLTK: The Natural Language Toolkit is another powerful library for text processing and segmentation.
- Stanford CoreNLP: A suite of NLP tools that includes sentence segmentation functionality.
Advantages of Server-Side Segmentation:
- Efficient Processing: PDF files are processed only once on the server. Afterward, the client can request the segmented sentences from a
.jsonfile, reducing the load on the client and speeding up the TTS process. - Accurate Sentence Segmentation: By using an NLP-based segmentation service, the system will accurately split sentences, minimizing errors compared to using regex.
- Better Performance: Since the segmentation is done only once during upload, subsequent client requests will be faster and more efficient, as they simply retrieve pre-processed data.
Disadvantages of Server-Side Segmentation:
- Increased Complexity: The system will be more complex to implement, as it requires an additional NLP service for sentence segmentation during PDF uploads.
- More Storage: The pre-processed segmented text needs to be stored alongside the original PDF file, slightly increasing storage requirements.
For a system handling large volumes of PDFs, Solution 2 (server-side segmentation) is more efficient and scalable. It avoids repetitive client-side processing, ensures accurate text segmentation, and allows for faster and smoother TTS generation. Although it requires more upfront work in terms of setting up the segmentation service and storage of additional .json files, the long-term benefits in performance and accuracy make it a better choice, especially for high-traffic systems.
The following is the updated high level system architecture diagram.
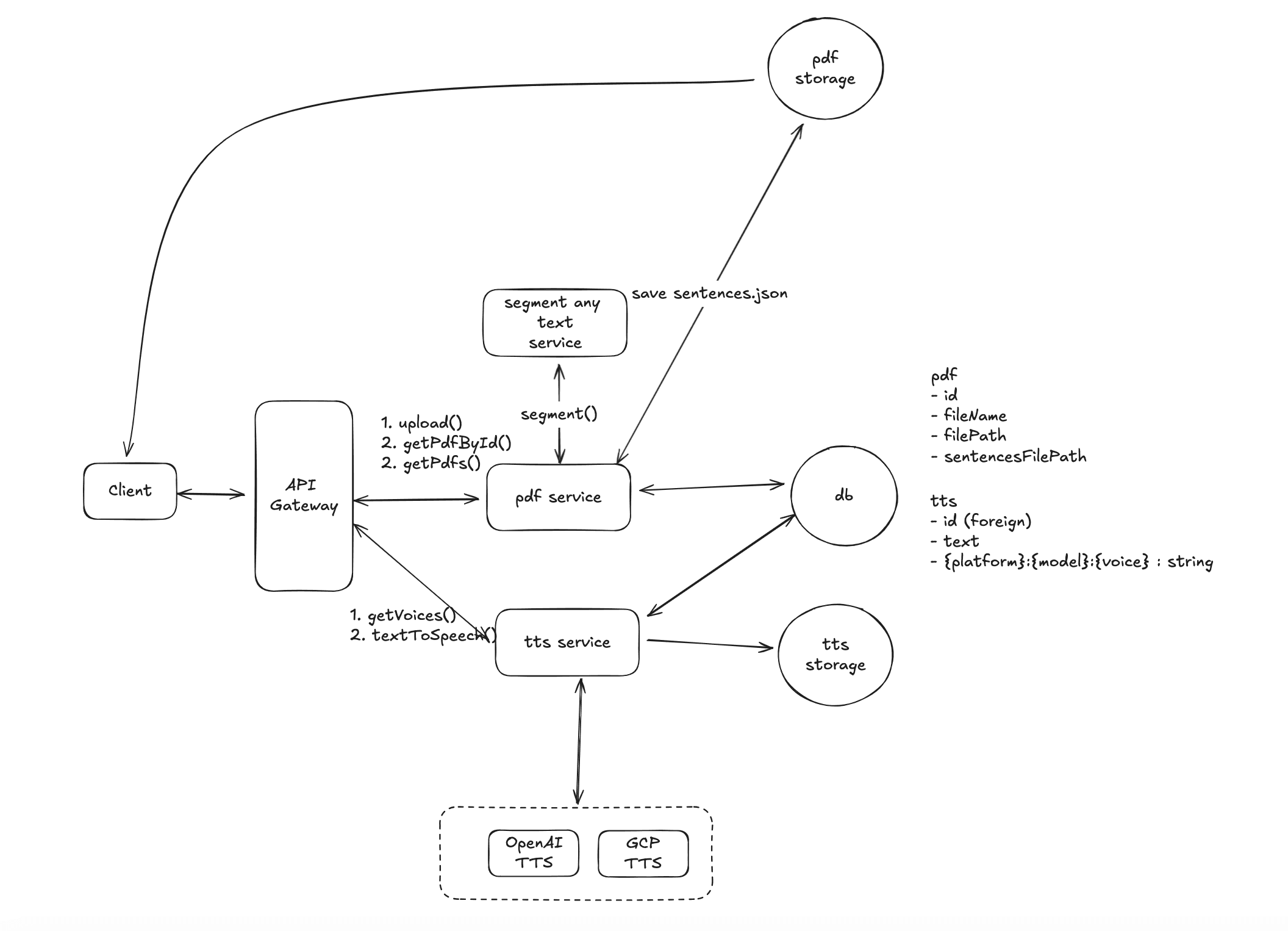
2. How to Implement Click-to-Read for Any Text in a PDF?
When reading a PDF, users often don’t want to start text-to-speech (TTS) from the beginning—they want to click on any sentence in the document and begin listening from there. Implementing this functionality requires accurately mapping the text in the PDF to its corresponding position on the screen. Here’s a step-by-step explanation of how to achieve this:
Step 1: Extract PDF Text and Positions Using pdfjs-dist
First, we need to parse the PDF and extract the text content along with its positional data. The pdfjs-dist library allows us to achieve this by providing the following structure:
TextItem Data Structure
{
text: 'Hello',
transform: [300, 0, 0, 10, 300, 500], // Position (x: 300px, y: 500px)
width: 100, // Width of the text box in pixels
height: 10 // Height of the text box in pixels
},
{
text: 'World',
transform: [300, 0, 0, 10, 0, 300], // Position (x: 300px, y: 500px)
width: 100, // Width of the text box in pixels
height: 10 // Height of the text box in pixels
}
In this example, the word "Hello" is located at (x: 300px, y: 500px) with a width of 100px and a height of 10px. The extracted text and position data form the basis for determining where each word or sentence is located on the PDF page.
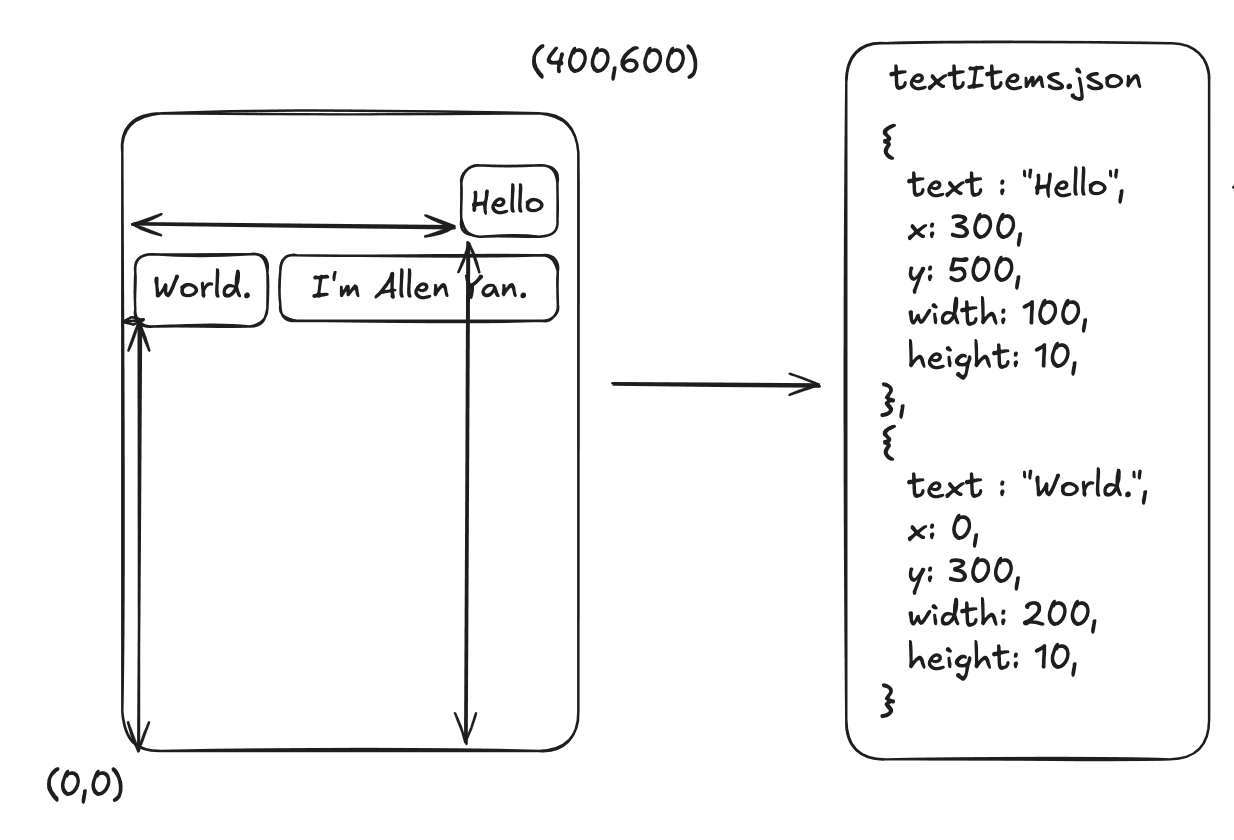
Step 2: Generate Sentence and Position Mapping
To implement click-to-read functionality, we need to map each sentence to its exact position on the PDF page. This is done by combining the sentence text (from sentences.json) with the positional information extracted from the PDF (from textItems.json).
sentences.json: Contains each sentence from the PDF, broken down into smaller chunks for TTS.textItems.json: Contains the exact positional data for each word or phrase, as extracted using pdfjs-dist.
Step 3: Create the highlights.json File
Using the data from both the sentences.json and textItems.json files, we can create a highlights.json file. This file will map each sentence to its corresponding rectangular coordinates (x, y, width, height) on the PDF.
highlights.json Structure
[
{
"sentence": "Hello Everyone.",
"rects": [
{
"x": 300,
"y": 500,
"width": 100,
"height": 10
},{
"x": 0,
"y": 300,
"width": 100,
"height": 10
}
]
},
{
"sentence": "I'm Allen.",
"rects": [
{
"x": 320,
"y": 520,
"width": 120,
"height": 10
}
]
}
]
In this structure, each sentence has a set of coordinates that define where it appears on the page. These coordinates can be used to create clickable areas on the document.
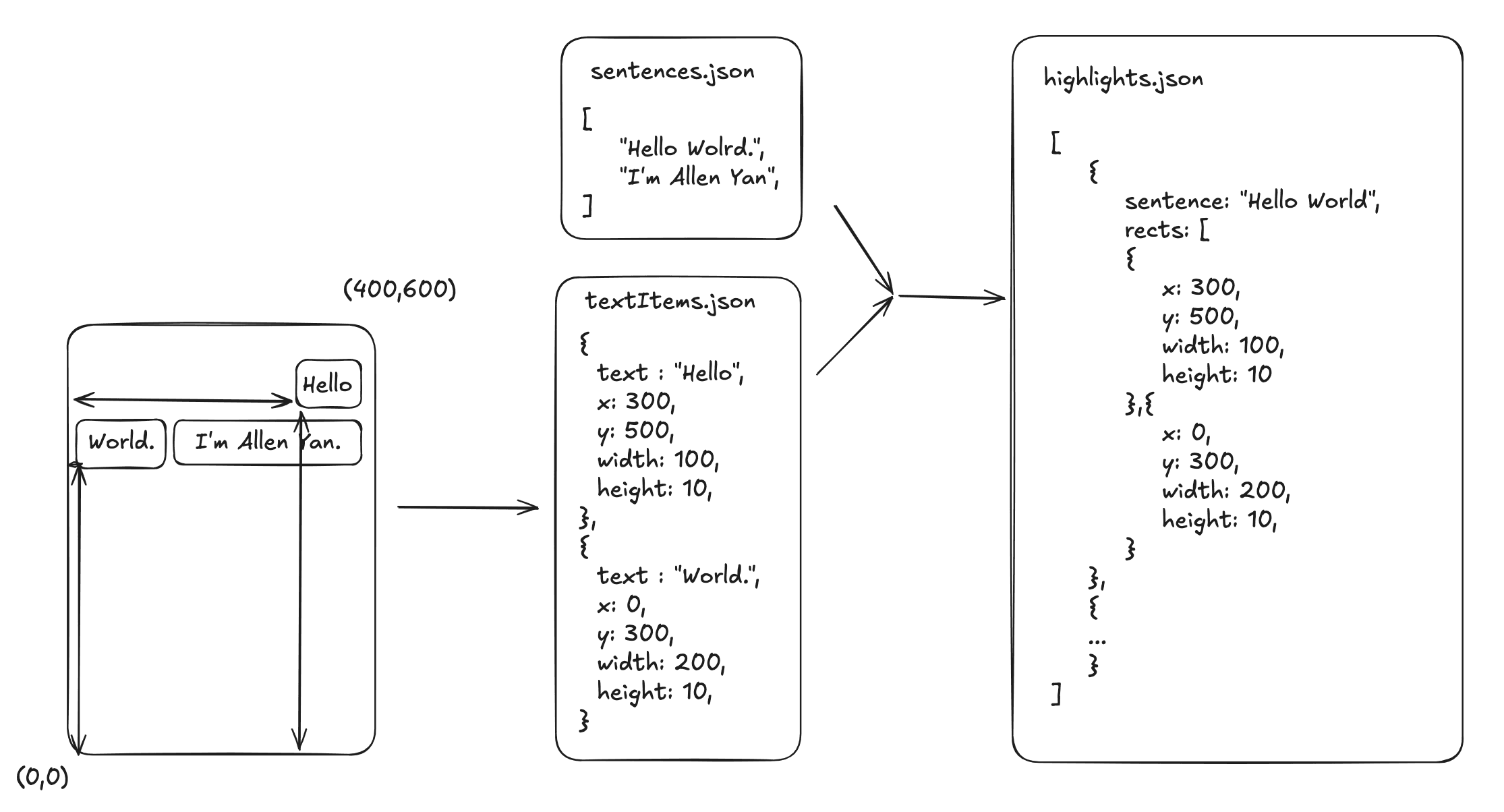
Step 4: Overlay Highlight and Clickable Areas
With the highlights.json file generated, the next step is to overlay a transparent layer on top of the PDF to detect clicks and display highlights. Here’s how this works:
- Highlight Layer: Using HTML/CSS, create a transparent layer on top of the PDF viewer. For each sentence, create an invisible clickable box based on the coordinates from
highlights.json. - Hover and Click Events: When the user hovers over or clicks a sentence, the highlight area becomes visible, and the corresponding TTS audio playback is triggered.
CSS for Highlight Box
.highlight-box {
position: absolute;
background-color: rgba(255, 255, 0, 0.3); /* Yellow highlight */
border: 1px solid rgba(255, 255, 0, 0.7);
cursor: pointer;
}
JavaScript for Handling Click
document.querySelectorAll('.highlight-box').forEach(box => {
box.addEventListener('click', function() {
const sentence = this.getAttribute('data-sentence');
playTTS(sentence); // Call TTS function with the clicked sentence
});
});
This allows users to click anywhere on the highlighted text in the PDF and begin TTS from that sentence.
Advantages of This Approach:
- Precise Sentence Selection: Users can click on any sentence to begin reading from that point, rather than having to listen from the start.
- Accurate Text Positioning: By using the extracted text data from pdfjs-dist, the system ensures that the clickable areas match the exact positions of the text on the PDF.
Implementing click-to-read functionality in a PDF requires mapping each sentence to its exact position on the document. By using pdfjs-dist to extract text and positional data, and by creating a highlights.json file to store the coordinates of each sentence, we can enable users to click anywhere in the document and trigger TTS playback. This approach, combined with efficient TTS caching, ensures a smooth and responsive user experience.
3. How to Handle User PDF Uploads During Peak Traffic?
During our capacity planning phase, we estimated an average traffic rate of 10k PDF uploads per second, with potential spikes reaching 30k/s during peak times. Given that processing a PDF can take several seconds, how can we design a system that ensures low latency and high throughput? Here are two possible solutions:
Solution 1: Decoupling PDF Processing with Asynchronous Queues
In this approach, we decouple the PDF service and the PDF processing service. The PDF processing service is horizontally scalable and can handle high traffic spikes by spinning up additional instances when necessary.
The architecture would look like this:
- PDF Service: When a user uploads a PDF, it is immediately stored, and a message is sent to a Kafka (or another message broker) queue with the document metadata and file path.
- PDF Processing Service: This service subscribes to the Kafka queue and asynchronously processes the uploaded PDFs. It extracts text, generates highlights, and prepares the file for further actions.
- Progress Tracking: Clients can either use polling or WebSocket connections to check the processing status of their document. The system updates the progress in real time, changing the document state from pending to processing, and finally to completed once all tasks are done.
Advantages:
- Horizontal Scalability: The PDF processing service can scale independently, allowing you to handle large bursts of traffic efficiently.
- Asynchronous Processing: The system ensures that PDF processing does not block the upload flow, leading to faster response times for the user.
Disadvantages:
- Real-time Monitoring: Some complexity is added to track document status and manage user expectations around document processing time.
Solution 2: Chunk-Based Processing
In this solution, we break down the PDF into smaller chunks and process them independently. For example, each chunk could represent 10 pages of the document. As each chunk is processed, the document metadata is updated, and the document state transitions from pending to processing.
- Chunking the PDF: When a PDF is uploaded, it is split into smaller, manageable pieces (chunks), each containing a certain number of pages (e.g., 10 pages per chunk).
- Parallel Processing: Each chunk is processed independently in parallel. As soon as a chunk is processed, the corresponding doc.state is updated from pending to processing, indicating partial availability.
- Client-Side Rendering: The client does not need to render the entire document at once. It requests the highlight data based on the current page number and the chunk index. For example, if the user is viewing page 21, the system will know to render chunkIndex = 2, retrieving highlights for that chunk only.
Advantages:
- Faster Feedback: Users don’t have to wait for the entire document to be processed before starting to interact with it. They can start viewing and interacting with parts of the document almost immediately.
- Efficient Resource Usage: By splitting large PDFs into smaller pieces, the system can handle multiple chunks in parallel, improving overall throughput and reducing processing times.
Disadvantages:
- Increased Complexity: Chunking the document and managing partial states for both the document and the highlights adds more complexity to both the backend processing and the client-side logic.
4. How to Avoid Duplicate TTS Requests Under High Concurrency and Prevent Resource Waste
When dealing with high-concurrency systems, it is crucial to ensure that identical TTS (text-to-speech) requests do not result in multiple audio files being generated for the same input. This not only wastes resources but can also lead to performance bottlenecks. Here’s how we can design a solution using a distributed lock with Redis to prevent duplicate TTS generation.
Solution: Redis Distributed Lock
Before making a TTS request to an external service (e.g., OpenAI or Google Cloud TTS), we can implement a Redis-based distributed lock to ensure that the same text is processed only once.
Conclusion
This blog post explores how to design a system for a PDF text-to-speech application similar to Speechify. We start by defining the system's functional scope, identifying the main entity classes and interfaces, and then create a simple high-level system architecture diagram. Next, we gradually improve our system design by meeting functional and non-functional requirements, such as high scalability and low latency.
To put this design concept into practice, I built DocWiser.com from scratch. This website serves as an alternative to Speechify, allowing users to import documents in various formats like PDF, TXT, and EPUB for text-to-speech reading. I also plan to develop Android and iOS versions in the future. Like Speechify.com, DocWiser.com offers a free trial, with subscriptions required only for advanced features.
Hi, I'm Ligang Yan, an independent software developer passionate about using innovative technologies to enhance our lives. Feel free to leave comments for discussion or contact me directly at wsyanligang@gmail.com.
